Enabling upcoming feature flags in an SPM package
As Swift evolves, a lot of new evolution proposals get merged into the language. Eventually these new language versions get shipped with Xcode, but sometimes you might want to try out Swift toolchains before they're available inside of Xcode.
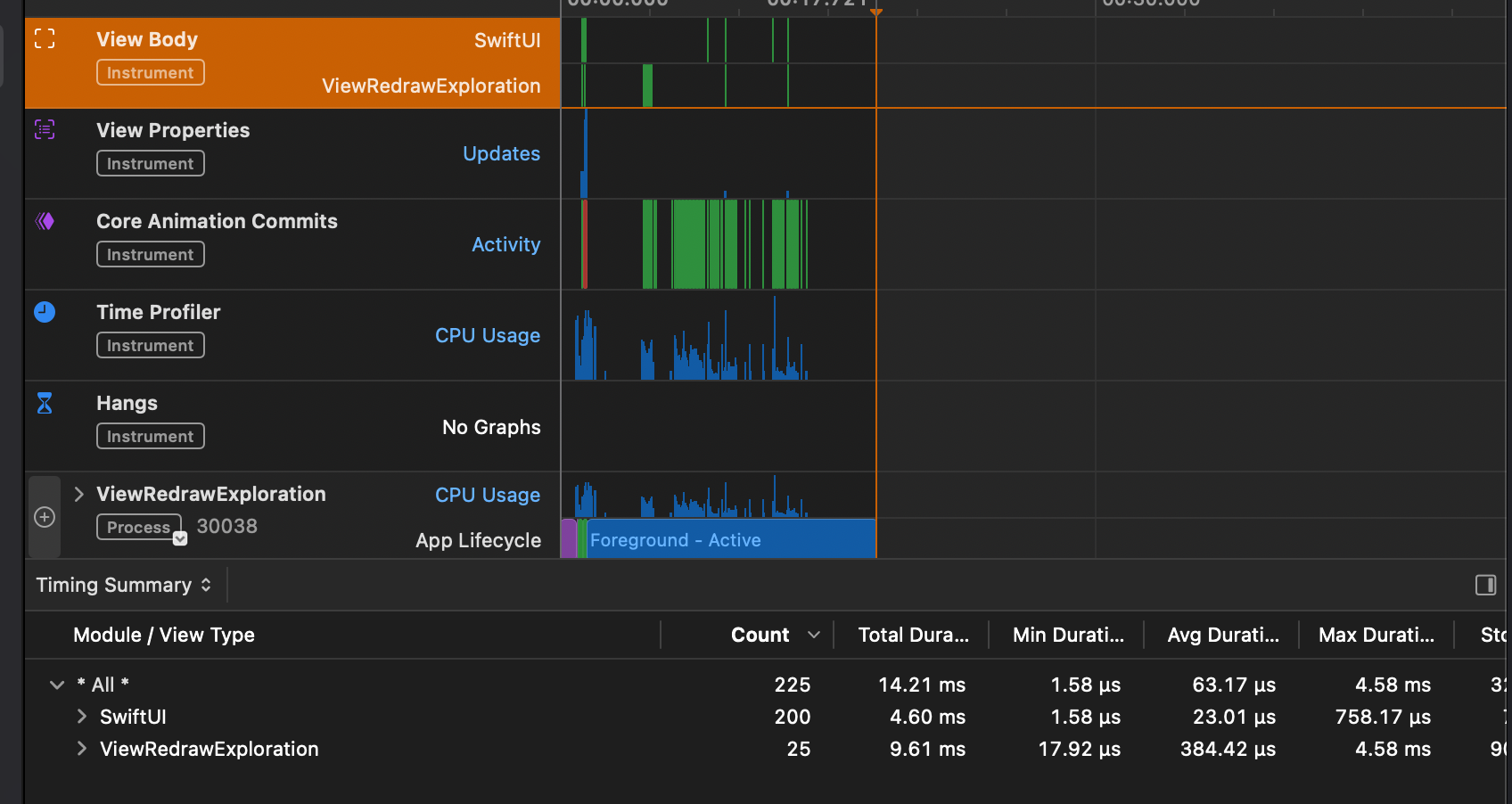
For example, I'm currently experimenting with Swift 6.2's upcoming features to see how they will impact certain coding patterns once 6.2 becomes available for everybody.
This means that I'm trying out proposals like SE-0461 that can change where nonisolated async functions run. This specific proposal requires me to turn on an upcoming feature flag. To do this in SPM, we need to configure the Package.json file as follows:
let package = Package(
name: "SwiftChanges",
platforms: [
.macOS("15.0")
],
targets: [
// Targets are the basic building blocks of a package, defining a module or a test suite.
// Targets can depend on other targets in this package and products from dependencies.
.executableTarget(
name: "SwiftChanges",
swiftSettings: [
.enableExperimentalFeature("NonisolatedNonsendingByDefault")
]
),
]
)The section to pay attention to is the swiftSettings argument that I pass to my executableTarget:
swiftSettings: [
.enableExperimentalFeature("NonisolatedNonsendingByDefault")
]You can pass an array of features to swiftSettings to enable multiple feature flags.
Happy experimenting!